Cách data visualization (trực quan hóa dữ liệu) tác động tới nhận thức của chúng ta về sự thật

Khi chúng ta nhìn vào một cuốn sách, xem tivi, sách báo hay quan sát người khác, chúng ta tự động đưa ra những nhận định, phán xét dựa trên những thông tin giới hạn mà chúng ta có.
Tất nhiên, chúng ta có quyền nhận định thế giới theo cách riêng của chúng ta. Tuy nhiên, với những thành kiến có sẵn, những nhận định nhanh chóng ấy có thể là những nhận định sai lầm.
Năm 2020, trong cuộc bầu cử tổng thống Mỹ, đã có nhiều tranh cãi xung quanh bản đồ hiển thị phiếu bầu khi đó. Lập luận được đưa ra là hình ảnh đại diện cho dữ liệu như vậy tạo ra sự thiên vị cho đảng có số phiếu chiếm ưu thế trong bang.
Data visualization được sử dụng để kể một câu chuyện, nó có thể định hướng nhận thức và niềm tin của chúng ta. Trong bài viết này, chúng ta sẽ sử dụng ví dụ về bản đồ trong cuộc bầu cử tổng thống Mỹ 2020 như một case study để hiểu vì sao biểu diễn đồ họa thông tin có thể dẫn tới nhận định sai lầm.
Thành kiến đến từ tư duy nhanh
Daniel Kahneman từng giải thích về tư duy của não trong cuốn Tư Duy Nhanh Chậm. Trong đó, não chúng ta có hai kiểu tư duy ứng với hai hệ thống là hệ thống 1 và hệ thống 2.
Hệ thống 1 là kiểu tư duy nhanh, dựa trên kỹ năng và thông tin có sẵn. Nó giúp chúng ta nhận định nhanh chóng vấn đề, tình trạng, bối cảnh. Ví dụ, chúng ta có thể nhanh chóng hiểu những tín hiệu từ người khác khi nói chuyện, hoặc lái xe mà không cần phải mất nhiều nỗ lực.
Hệ thống 2 là tư duy chậm, là hệ thống phân tích, đòi hỏi sự chú ý, tập trung. Hệ thống này hoạt động khi chúng ta phải giải quyết vấn đề phức tạp, cần nhiều nỗ lực của ý thức.
Khi chúng ta bắt gặp một sự vật, sự việc, hệ thống 1 sẽ sử dụng những thông tin có sẵn trong não bộ để đưa ra những nhận định về chúng. Dù nhận định này có thể sai nhưng hệ thống 2 cũng thường chấp nhận những nhận định tự động ấy. Trừ khi có gì đó bất thường, không đúng với thành kiến có sẵn của chúng ta, việc phân tích mới bắt đầu được tiến hành.
Kahneman giải thích rằng hệ thống 1 có thể xây dựng một câu chuyện hợp lý chỉ được tiếp nhận một chút thông tin từ bên ngoài. Ví dụ, nếu bạn thấy một bạn mắc quần jeans, áo phông, đeo tai nghe ngồi ôm điện thoại, khả năng cao bạn sẽ đoán họ là học sinh, bởi ngoại hình ấy phù hợp với thành kiến của bạn về học sinh.
Tương tự với data visualization, hệ thống 1 tin vào bất cứ câu chuyện nào phù hợp với thành kiến có sẵn, dù nó đúng hay sai.
Data visualization kể những câu chuyện khác
Tại thời điểm tôi xuất bản bài viết này, hẳn những tranh luận về bản đồ bầu cử vẫn còn được tiếp diễn. Bởi ngay trong lúc này, dữ liệu về số phiếu đáng được tham chiếu dưới nhiều bản đồ với cách thể hiện dữ liệu khác nhau. Những bản đồ ấy cho thấy một sự sai lệch lớn trong cách thể hiện thông tin của bạn đồ chính thức.
Hai bản đồ, hai câu chuyện
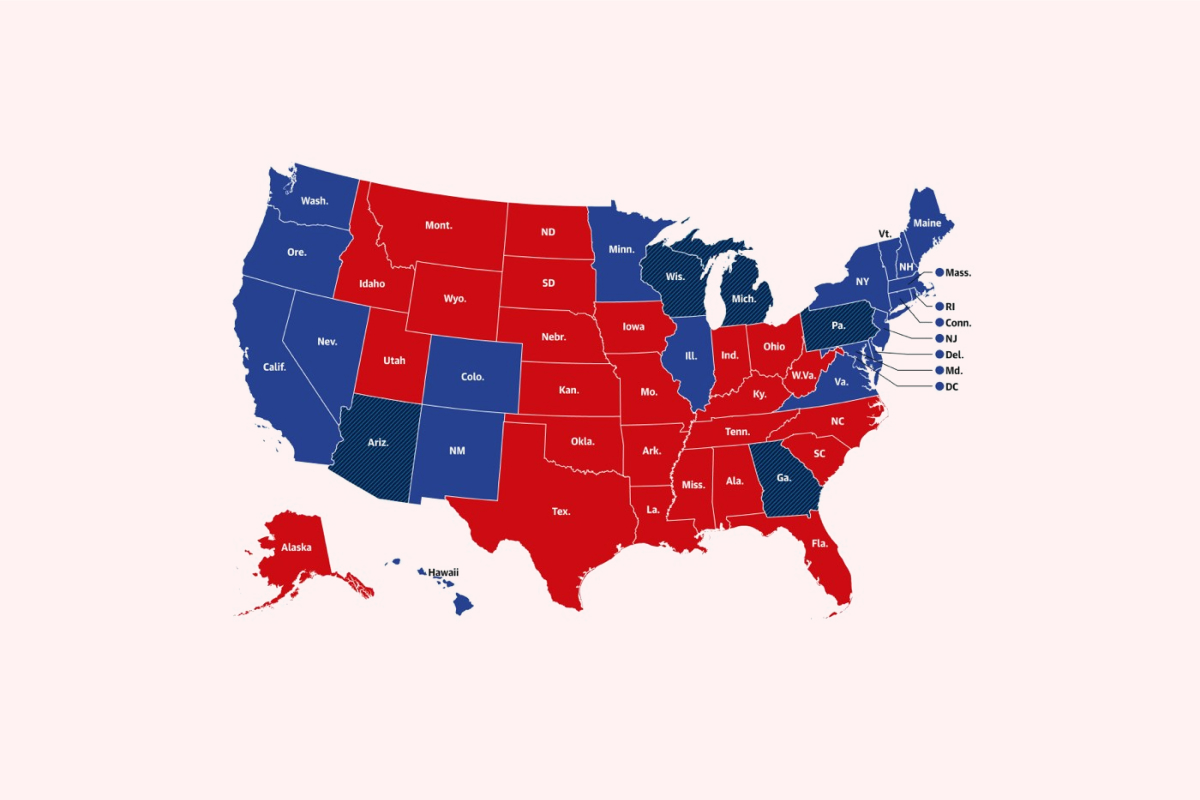
Với bản đồ trên, chúng ta có thể thấy số phiếu đại diện cho bang chứ không phải công dân. Cách thể hiện dữ liệu như vậy khiến chúng ta hiểu nhầm là đảng Cộng hòa (đỏ) đang có nhiều phiếu hơn đảng Dân chủ (xanh), dù vốn đảng Dân chủ có số phiếu lớn hơn.
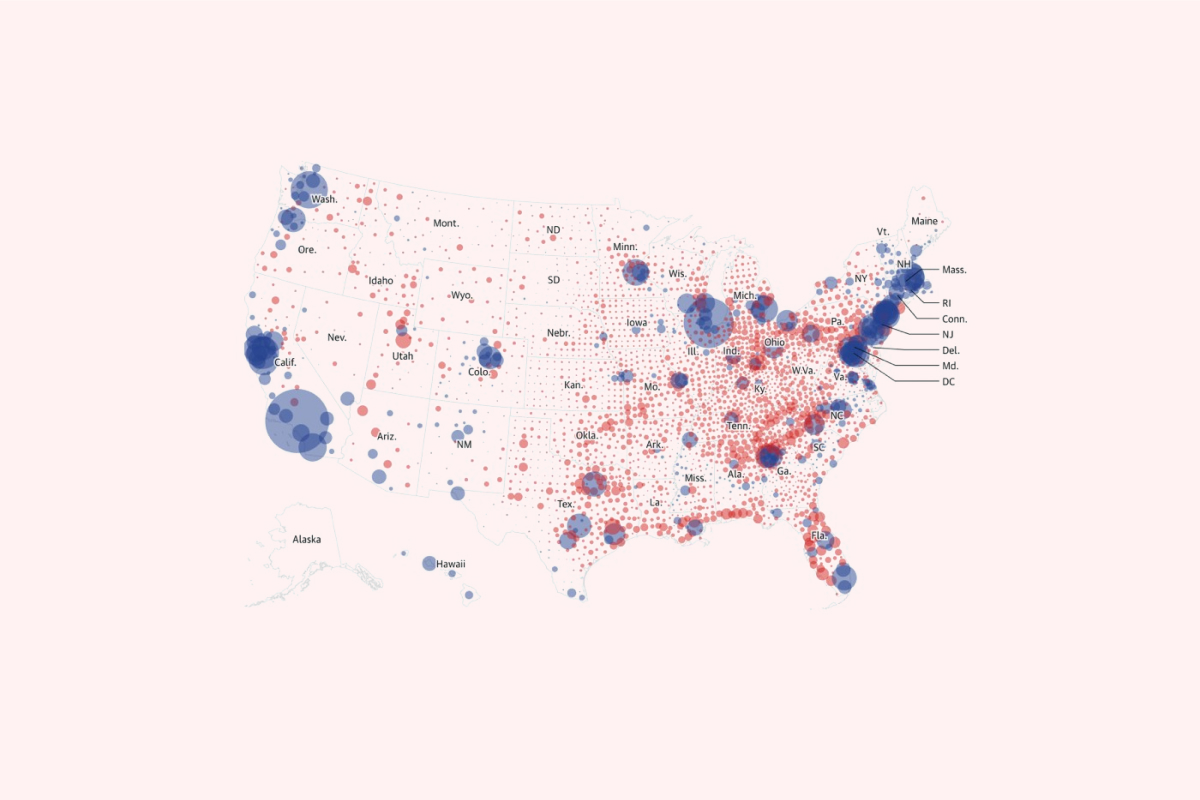
Trong một bản đồ khác, với cách thể hiện dữ liệu khác, chúng ta có thể thấy đảng Dân chủ chiếm ưu thế hơn hẳn.
Tuy nhiên, theo dữ liệu thô, số phiếu của hai đảng chỉ có 4% chênh lệch. Với số chênh lệch nhỏ như vậy, khó có bản đồ nào có thể chỉ ra đúng sự thật. Chúng ta có thể nói là cả hai bản đồ đều phần nào tách khỏi sự thật và mỗi bản đồ lại tạo thành một nhận thức và niềm tin về sự thật riêng.
Phân tích kỹ hơn, bản đồ thứ nhất thể hiện cho số phiếu đa số của một bang nhưng thực tế là tỷ lệ dân số giữa các bang khác nhau nhưng nó không thể hiện được điều ấy. Bản đồ thứ hai cố gắng giải quyết vấn đề này bằng cách thể hiện lượng vote bằng khích và độ đậm nhạt của các chấm tròn. Tuy nhiên, lúc này chúng ta tập trung vào những chấm tròn màu xanh có kích thước lớn tại vùng ven biển, khiến chúng ta cảm tưởng tỷ lệ phiếu bầu nghiêng hẳn về Dân chủ.
Khi nhìn những bản đồ trên, hệ thống tư duy nhanh của chúng ta lập tức đưa ra nhận định, dù nhận định ấy đúng hay sai. Đó là vấn đề lớn nhất trong việc thể hiện dữ liệu qua hình ảnh, bởi dữ liệu có thể bị thao túng để kể một câu chuyện sai sự thật.
Thành kiến có thể làm sai lệch cảm nhận về thực tế
Có nhiều cách mà data visualization có thể bóp méo nhận thức của chúng ta về thực tế. Dưới đây là một số hiệu ứng tâm lý thường gặp:
Đánh giá khả năng
Theo Daniel Kahneman và Amos Nathan Tversky, hiệu ứng availability heuristic cho phép chúng ta đưa ra kết luận nhanh khi chúng ta cần. Dù nó hữu ích trong nhiều trường hợp nhưng nó cũng tạo ra những đánh giá sai lầm.
Ví dụ, sau khi thấy nhiều tin về máy bay rơi, bạn dần hình thành nhận thức rằng đi máy bay không an toàn. Vậy nên, trong chuyến du lịch tiếp theo, bạn quyết định không đi máy bay vì tin có khả năng cao sẽ gặp tai nạn.
Đóng khung nhận thức
Việc chúng ta đóng khung nhận thức tác động tới cách chúng ta xây dựng thực tế cá nhân và nó vốn khác với thực tế khách quan. Ví dụ, nếu có hai chai rượu, chai có giá đắt hơn sẽ cho cảm tưởng rằng nó có chất lượng cao hơn và đáng tiền hơn. Đóng khung nhận thức có thể được tham chiếu trên giá cả, màu sắc, giọng điệu.
Điểm neo
Điểm neo điều chỉnh hành vi và thái độ của chúng ta tùy theo bối cảnh. Ví dụ như cách chúng ta hành xử khi đi mua sắm ở cửa hàng giảm giá sẽ khác với khi đi mua một căn nhà.
Khi chúng ta nhận tín hiệu từ môi trường ngoài, các quyết định của chúng ta tự động bị ảnh hưởng bởi điểm neo ấy. Nghiên cứu cho thấy chúng ta thường bị hấp dẫn bởi hàng giảm giá, dù lúc ấy có thể có lựa chọn rẻ hơn. Ví dụ, trên quầy nước ngọt siêu thị, nếu dán nhãn “giới hạn mua cho mỗi khách là 12 lon” có thể khiến khách hàng có xu hướng mua nhiều hơn.
Đặc điểm đại diện
Một hiệu ứng khác được chỉ ra bởi Tversky and Kahneman, đặc điểm đại diện tác động tới quá trình nhận định, dù nó cũng có thể dẫn tới những nhận định hoặc lựa chọn sai.
Ví dụ, bạn đang chờ xe bus và thấy một người có khuôn mặt dữ tợn, dù không có bất cứ thông tin nào về người ấy nhưng bạn vẫn có hình dung rằng có thể là người xấu, tội phạm, không nên tin tưởng.
Kết luận
Não của chúng ta là một bộ máy, luôn tìm cách giải thích thực tế theo những câu chuyện nó đã quen. Dù có tự nhận thấy mình là người khách quan tới đâu, chúng ta vẫn luôn có những định kiến dựa trên những trải nghiệm, thông tin chúng ta có sẵn.
Giống như chúng ta đã thấy trong bản đồ bầu cử Mỹ, data visualization có thể không hoàn toàn kể sự thật và chúng ta thường không nhận ra điều ấy. Vậy nên, khi đứng trước một biểu đồ dữ liệu, thay vì vội vàng đưa ra kết luận, chúng ta nên xem xét thêm các số liệu thô để có thể nhìn nhận khách quan nhất.
Bài viết
liên quan


Chiến lược
/ 01 Th11, 2022Tại sao Website quan trọng với doanh nghiệp?

UX/UI
/ 01 Th11, 2022Tối ưu CX (trải nghiệm khách hàng) với sơ đồ hành trình khách hàng (CJM)

Chiến lược
/ 01 Th11, 2022Sự thay đổi trong hành trình trải nghiệm khách hàng CX của ngành hàng không

UX/UI
/ 01 Th11, 2022Bạn có đang nhầm lẫn giữa sơ đồ hành trình khách hàng và luồng người dùng?

